Welcome to our completed projects showcase page! Here, we present our research achievements in our ASPIRE-MWI research initiative. You may access the manuscript by clicking the corresponding project image.
Collaboration with our international ASPIRE-MWI PIs
International collaboration
Japan team only
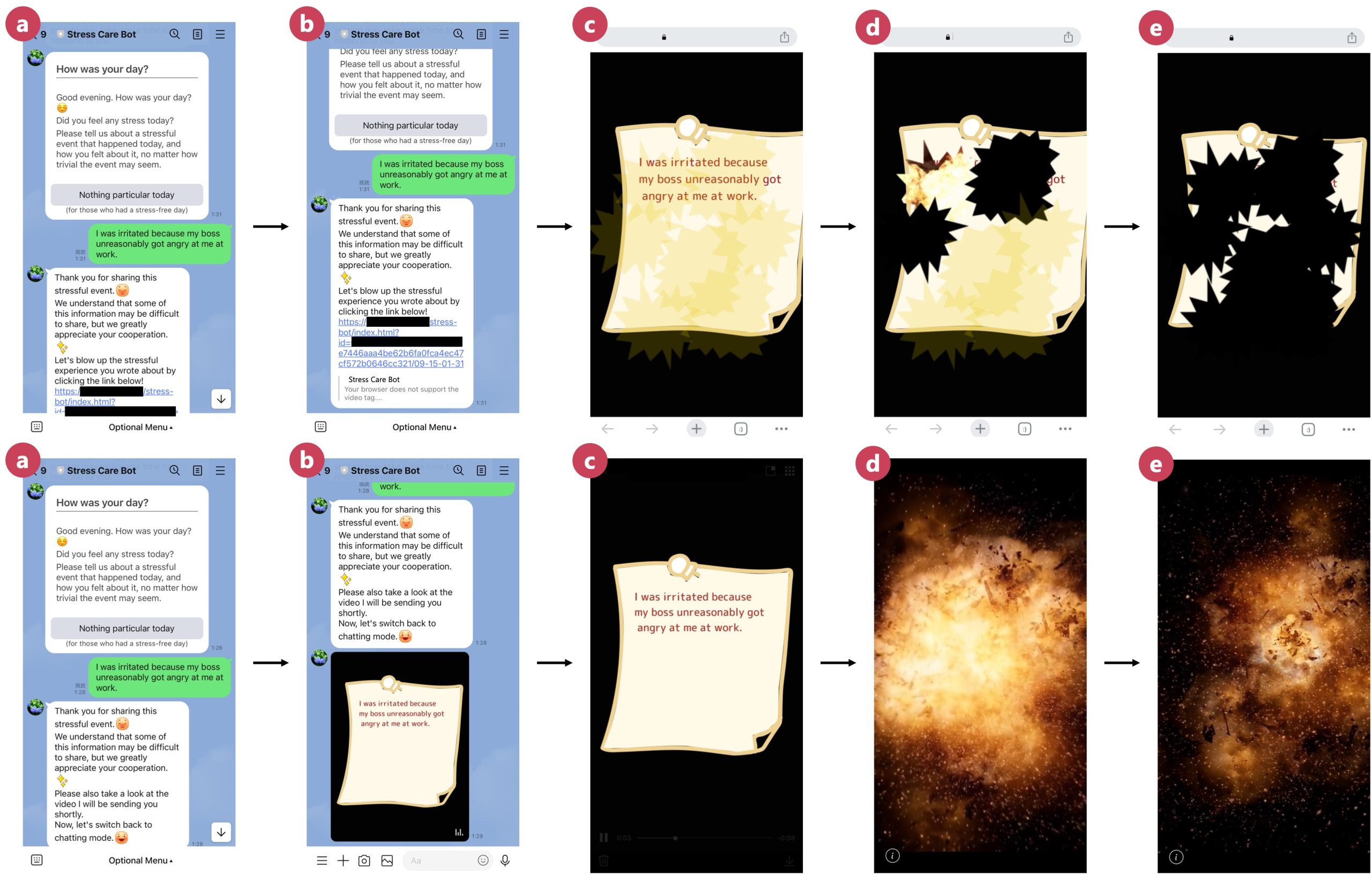
Examining Input Modalities and Visual Feedback Designs in Mobile Expressive Writing
Shunpei Norihama, Shixian Geng, Kakeru Miyazaki, Arissa J. Sato, Mari Hirano, Simo Hosio, and Koji Yatani
MobileHCI 2025
Abstract
Expressive writing is an established approach for stress management. Recently, information technologies, such as smartphones, have also been explored for expressive writing. Although mobile interfaces have the potential to support various daily writing activities, interface designs for mobile expressive writing and their effects on stress relief still lack empirical understanding. We examined the interface design of mobile expressive writing by investigating the influence of input modalities and visual feedback designs on usability and perceived cathartic effects through field studies. While our studies confirmed the stress-relieving effects of mobile expressive writing, our results offer important insights into interface design. We found keyboard-based text entry more suited and preferred over voice messages for its privacy and reflective nature. Participants expressed different reasons for preferring different post-writing visual feedback depending on the cause and type of stress. This work advances interface design for mobile expressive writing and deepens understanding of its effects.
Multi-player approaches for dueling bandits
‘
Or Raveh, Junya Honda, Masashi Sugiyama
AISTATS 2025
Abstract
Fine-tuning large deep networks with preference-based human feedback has seen promising results. As user numbers grow and tasks shift to complex datasets like images or videos, distributed approaches become essential for efficiently gathering feedback. To address this, we introduce a multiplayer dueling bandit problem, highlighting that exploring non-informative candidate pairs becomes especially challenging in a collaborative environment. We demonstrate that the use of a Follow Your Leader black-box approach matches the asymptotic regret lower-bound when utilizing known dueling bandit algorithms as a foundation. Additionally, we propose and analyze a message-passing fully distributed approach with a novel Condorcet-Winner recommendation protocol, resulting in expedited exploration in the non-asymptotic regime which reduces regret. Our experimental comparisons reveal that our multiplayer algorithms surpass single-player benchmark algorithms, underscoring their efficacy in addressing the nuanced challenges of this setting.
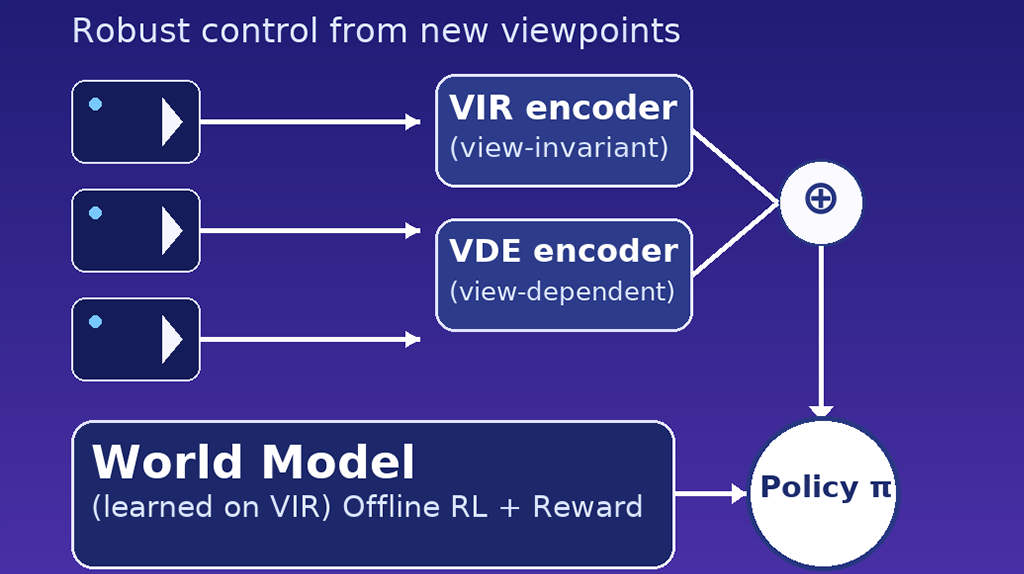
Learning view-invariant world models for visual robotic manipulation
Jing-Cheng Pang, Nan Tang, Kaiyuan Li, Yuting Tang, Xin-Qiang Cai, Zhen-Yu Zhang, Gang Niu, Masashi Sugiyama, Yang Yu
ICLR 2025
Abstract
Robotic manipulation tasks often rely on visual inputs from cameras to perceive the environment. However, previous approaches still suffer from performance degradation when the camera’s viewpoint changes during manipulation. In this paper, we propose ReViWo (Representation learning for View-invariant World model), leveraging multi-view data to learn robust representations for control under viewpoint disturbance. ReViWo utilizes an autoencoder framework to reconstruct target images by an architecture that combines view-invariant representation (VIR) and view-dependent representation. To train ReViWo, we collect multi-view data in simulators with known view labels, meanwhile, ReViWo is simutaneously trained on Open X-Embodiment datasets without view labels. The VIR is then used to train a world model on pre-collected manipulation data and a policy through interaction with the world model. We evaluate the effectiveness of ReViWo in various viewpoint disturbance scenarios, including control under novel camera positions and frequent camera shaking, using the Meta-world & PandaGym environments. Besides, we also conduct experiments on real world ALOHA robot. The results demonstrate that ReViWo maintains robust performance under viewpoint disturbance, while baseline methods suffer from significant performance degradation. Furthermore, we show that the VIR captures task-relevant state information and remains stable for observations from novel viewpoints, validating the efficacy of the ReViWo approach.
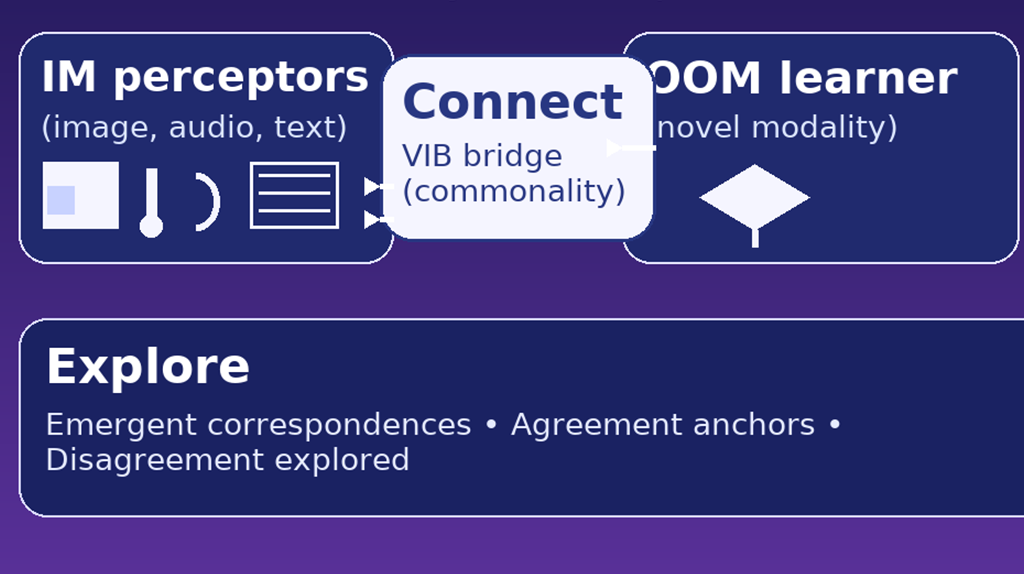
Towards out-of-modal generalization without instance-level modal correspondence
Zhuo Huang , Gang Niu, Bo Han, Masashi Sugiyama, Tongliang Liu
ICLR 2025
Abstract
The world is understood from various modalities, such as appearance, sound, language, etc. Since each modality only partially represents objects in a certain physical meaning, leveraging additional ones is beneficial in both theory and practice. However, exploiting novel modalities normally requires cross-modal pairs corresponding to the same instance, which is extremely resource-consuming and sometimes even impossible, making knowledge exploration of novel modalities largely restricted. To seek practical multi-modal learning, here we study Out-of-Modal (OOM) Generalization as an initial attempt to generalize to an unknown modality without given instance-level modal correspondence. Specifically, we consider Semi-Supervised and Unsupervised scenarios of OOM Generalization, where the first has scarce correspondences and the second has none, and propose connect & explore (COX) to solve these problems. COX first connects OOM data and known In-Modal (IM) data through a variational information bottleneck framework to extract shared information. Then, COX leverages the shared knowledge to create emergent correspondences, which is theoretically justified from an information-theoretic perspective. As a result, the label information on OOM data emerges along with the correspondences, which help explore the OOM data with unknown knowledge, thus benefiting generalization results. We carefully evaluate the proposed COX method under various OOM generalization scenarios, verifying its effectiveness and extensibility.

Towards effective evaluations and comparison for LLM unlearning methods.
Qizhou Wang, Bo Han, Puning Yang, Jianing Zhu, Tongliang Liu, Masashi Sugiyama
ICLR 2025
Abstract
The imperative to eliminate undesirable data memorization underscores the significance of machine unlearning for large language models (LLMs). Recent research has introduced a series of promising unlearning methods, notably boosting the practical significance of the field. Nevertheless, adopting a proper evaluation framework to reflect the true unlearning efficacy is also essential yet has not received adequate attention. This paper seeks to improve the evaluation of LLM unlearning by addressing two key challenges—a) the robustness of evaluation metrics and b) the trade-offs between competing goals. The first challenge stems from findings that current metrics are susceptible to various red teaming scenarios. It indicates that they may not reflect the true extent of knowledge retained by LLMs but rather tend to mirror superficial model behaviors, thus prone to attacks. We address this issue by devising and assessing a series of candidate metrics, selecting the most robust ones under various types of attacks. The second challenge arises from the conflicting goals of eliminating unwanted knowledge while retaining those of others. This trade-off between unlearning and retention often fails to conform the Pareto frontier, rendering it subtle to compare the efficacy between methods that excel only in either unlearning or retention. We handle this issue by proposing a calibration method that can restore the original performance on non-targeted data after unlearning, thereby allowing us to focus exclusively on assessing the strength of unlearning. Our evaluation framework notably enhances the effectiveness when assessing and comparing various LLM unlearning methods, further allowing us to benchmark existing works, identify their proper hyper-parameters, and explore new tricks to enhance their practical efficacy.
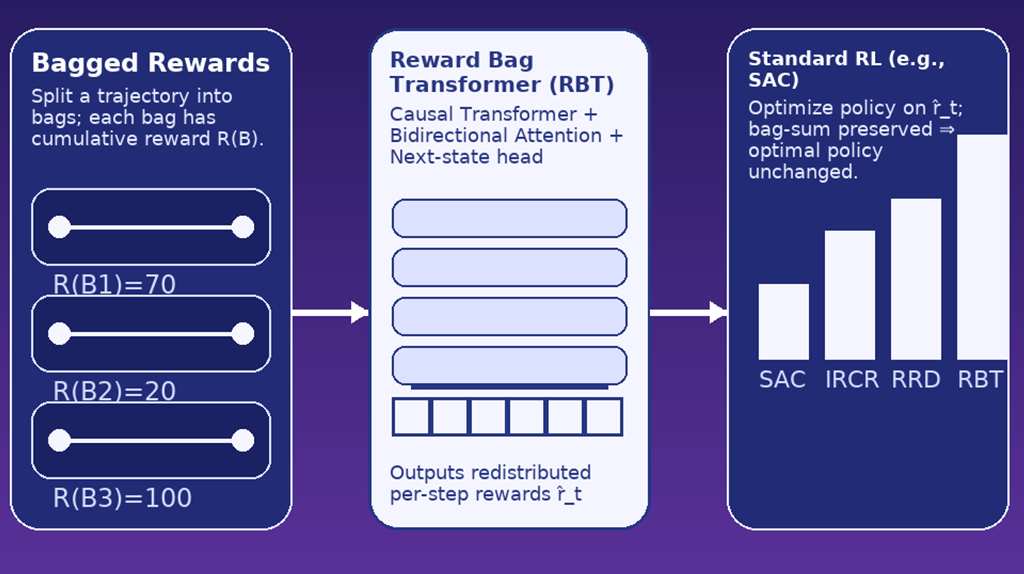
Reinforcement learning from bagged reward
A
Yuting Tang, Xin-Qiang Cai, Yao-Xiang Ding, Qiyu Wu, Guoqing Liu, Masashi Sugiyama
TMLR 2025
Abstract
In Reinforcement Learning (RL), it is commonly assumed that an immediate reward signal is generated for each action taken by the agent, helping the agent maximize cumulative rewards to obtain the optimal policy. However, in many real-world scenarios, designing immediate reward signals is difficult; instead, agents receive a single reward that is contingent upon a partial sequence or a complete trajectory. In this work, we define this challenging problem as RL from Bagged Reward (RLBR), where sequences of data are treated as bags with non-Markovian bagged rewards, leading to the formulation of Bagged Reward Markov Decision Processes (BRMDPs). Theoretically, we demonstrate that RLBR can be addressed by solving a standard MDP with properly redistributed bagged rewards allocated to each instance within a bag. Empirically, we find that reward redistribution becomes more challenging as the bag length increases, due to reduced informational granularity. Existing reward redistribution methods are insufficient to address these challenges. Therefore, we propose a novel reward redistribution method equipped with a bidirectional attention mechanism, enabling the accurate interpretation of contextual nuances and temporal dependencies within each bag. We experimentally demonstrate that the proposed method consistently outperforms existing approaches.
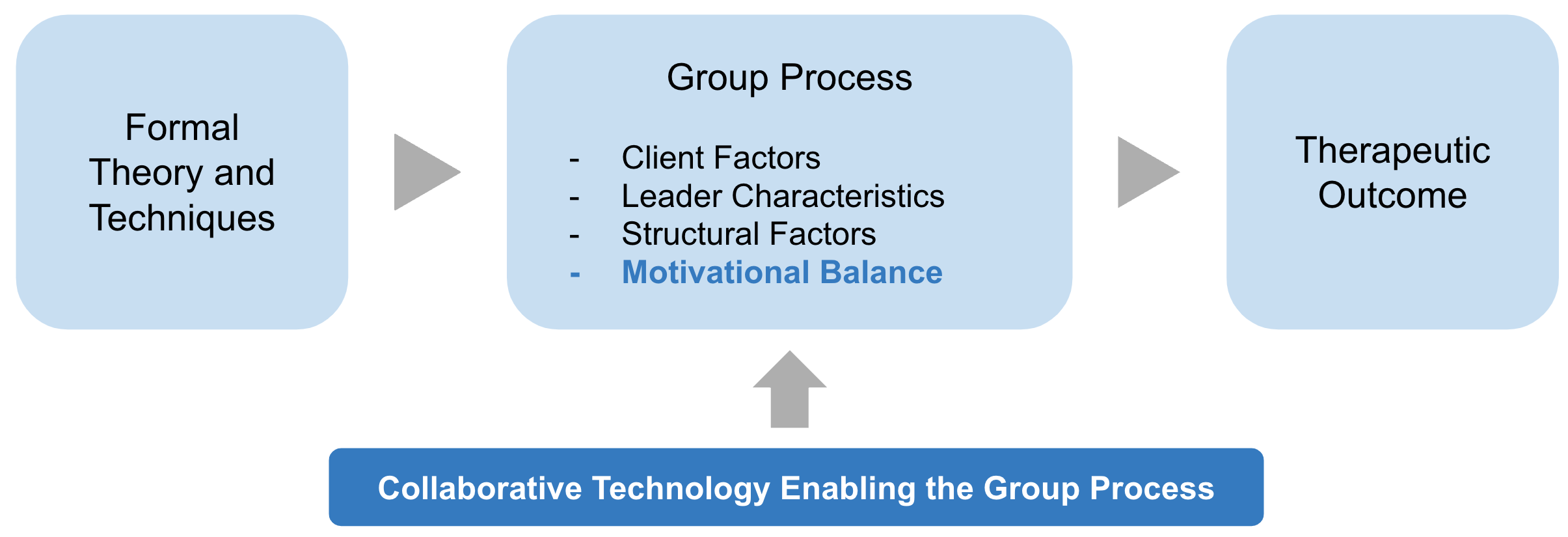
When Group Spirit Meets Personal Journeys: Exploring Motivational Dynamics and Design Opportunities in Group Therapy
Geng Shixian, Shimojima Ginshi, Yang, Chi-Lan, Sramek Zefan, Norihama Shunpei, Takano Ayumi, Hosio Simo, Yatani Koji
CSCW 2025
Abstract
Psychotherapy, such as cognitive-behavioral therapy (CBT), is effective in treating various mental disorders. Technology-facilitated mental health therapy improves client engagement through methods like digitization or gamification. However, these innovations largely cater to individual therapy, ignoring the potential of group therapy-a treatment for multiple clients concurrently, which enables individual clients to receive various perspectives in the treatment process and also addresses the scarcity of healthcare practitioners to reduce costs. Notwithstanding its cost-effectiveness and unique social dynamics that foster peer learning and community support, group therapy, such as group CBT, faces the issue of attrition. While existing medical work has developed guidelines for therapists, such as establishing leadership and empathy to facilitate group therapy, understanding about the interactions between each stakeholder is still missing. To bridge this gap, this study examined a group CBT program called the Serigaya Methamphetamine Relapse Prevention Program (SMARPP) as a case study to understand stakeholder coordination and communication, along with factors promoting and hindering continuous engagement in group therapy. In-depth interviews with eight facilitators and six former clients from SMARPP revealed the motivators and demotivators for facilitator-facilitator, client-client, and facilitator-client communications. Our investigation uncovers the presence of discernible conflicts between clients’ intrapersonal motivation as well as interpersonal motivation in the context of group therapy through the lens of self-determination theory. We discuss insights and research opportunities for the HCI community to mediate such tension and enhance stakeholder communication in future technology-assisted group therapy settings.
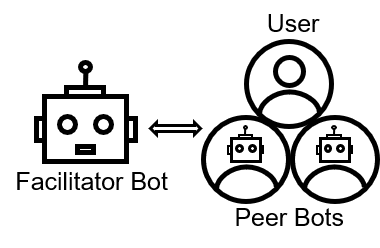
Beyond the Dialogue: Multi-chatbot Group Motivational Interviewing for Premenstrual Syndrome (PMS) Management
A
Geng Shixian, Inayoshi Remi, Yang Chi-Lan, Sramek Zefan, Umeda Yuya, Kasahara Chiaki, Sato J Arissa, Hosio Simo, Yatani Koji
CHI 2025
Abstract
Premenstrual syndrome (PMS) is a prevalent disorder among women, often exacerbated by a lack of peer support due to associated stigmatization. Drawing inspiration from the established benefits of group therapy, particularly the sense of belonging it fosters, we developed a multi-chatbot group motivational interviewing system. The system consists of a facilitator bot and two peer bots, and simulates a group counseling environment for PMS management using Large Language Models (LLMs). We conducted a study with 63 participants and divided them into three conditions (no intervention, 1-on-1 chatbot, group chatbots) over two menstruation cycles for evaluation. Our findings revealed that participants in the group chat condition exhibited higher levels of engagement and language convergence with the chatbots. These participants were also able to engage in social learning and demonstrated motivation in coping through interactions with the chatbots. Finally, we discuss design implications for multi-chatbot interactions in supporting mental health.

Asian Emotional Body Movement Database: Diverse Intercultural E-Motion Database of Asian Performers (DIEM-A)
A
Miao Cheng, Chia-huei Tseng, Ken Fujiwara, Victor Schneider, Yoshifumi Kitamura
ACII 2025
Abstract
In this paper, we introduce the Diverse Intercultural E-Motion Database of Asian Performers (DIEM-A), high-quality motion-capture data from 97 Asian professional performers (54 Japanese, 43 Taiwanese). Each performer enacted 12 emotions across 3 self-created scenarios at 3 intensity levels, plus 3 additional neutral scenarios, resulting in a total of 10,767 motion recordings accompanied by videos and textual scenario descrip- tions. Preliminary evaluations indicated robust overall emotion recognition accuracy and highlighted how scenario context, performer styles, and cultural factors jointly influenced emotional understanding from body motions. We discuss potential interdis- ciplinary applications of DIEM-A in affective computing, cogni- tive and social neuroscience, cross-cultural comparison studies, and human-computer interaction by offering rich, ecologically valid data on expressive bodily behavior.
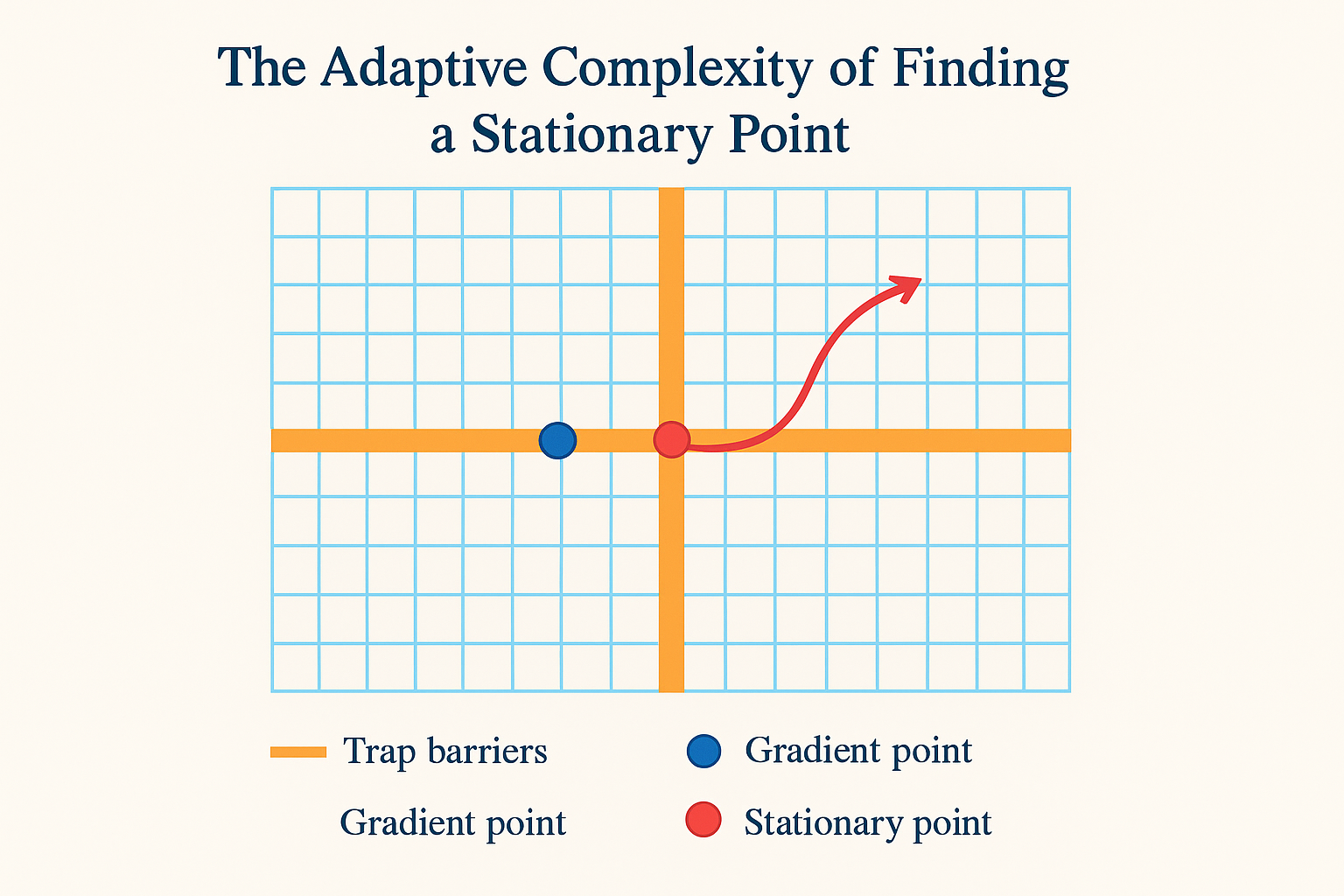
The adaptive complexity of finding a stationary point
A
Zhou Huanjian, Han Andi, Takeda Akiko, Masashi Sugiyama
COLT 2025
Abstract
In large-scale applications, such as machine learning, it is desirable to design non-convex optimization algorithms with a high degree of parallelization. In this work, we study the adaptive complexity of finding a stationary point, which is the minimal number of sequential rounds required to achieve stationarity given polynomially many queries executed in parallel at each round. For the high-dimensional case, \emph{i.e.}, d=Ω˜(ε−(2+2p)/p) , we show that for any (potentially randomized) algorithm, there exists a function with Lipschitz p -th order derivatives such that the algorithm requires at least ε−(p+1)/p iterations to find an ε -stationary point. Our lower bounds are tight and show that even with poly(d) queries per iteration, no algorithm has better convergence rate than those achievable with one-query-per-round algorithms. In other words, gradient descent, the cubic-regularized Newton’s method, and the p -th order adaptive regularization method are adaptively optimal. Our proof relies upon novel analysis with the characterization of the output for the hardness potentials based on a chain-like structure with random partition. For the constant-dimensional case, \emph{i.e.}, d=Θ(1) , we propose an algorithm that bridges grid search and gradient flow trapping, finding an approximate stationary point in constant iterations. Its asymptotic tightness is verified by a new lower bound on the required queries per iteration. We show there exists a smooth function such that any algorithm running with Θ(log(1/ε)) rounds requires at least Ω˜((1/ε)(d−1)/2) queries per round. This lower bound is tight up to a logarithmic factor, and implies that the gradient flow trapping is adaptively optimal.

Parallel simulation for sampling under isoperimetry and score-based diffusion models
Zhou Huanjian, Masashi Sugiyama
ICML 2025
Abstract
Sampling from high-dimensional probability distributions is fundamental in machine learning and statistics. As datasets grow larger, computational efficiency becomes increasingly important, particularly in reducing adaptive complexity, namely the number of sequential rounds required for sampling algorithms. While recent works have introduced several parallelizable techniques, they often exhibit suboptimal convergence rates and remain significantly weaker than the latest lower bounds for log-concave sampling. To address this, we propose a novel parallel sampling method that improves adaptive complexity dependence on dimension d reducing it from O˜(log2d) to O˜(logd). Our approach builds on parallel simulation techniques from scientific computing.
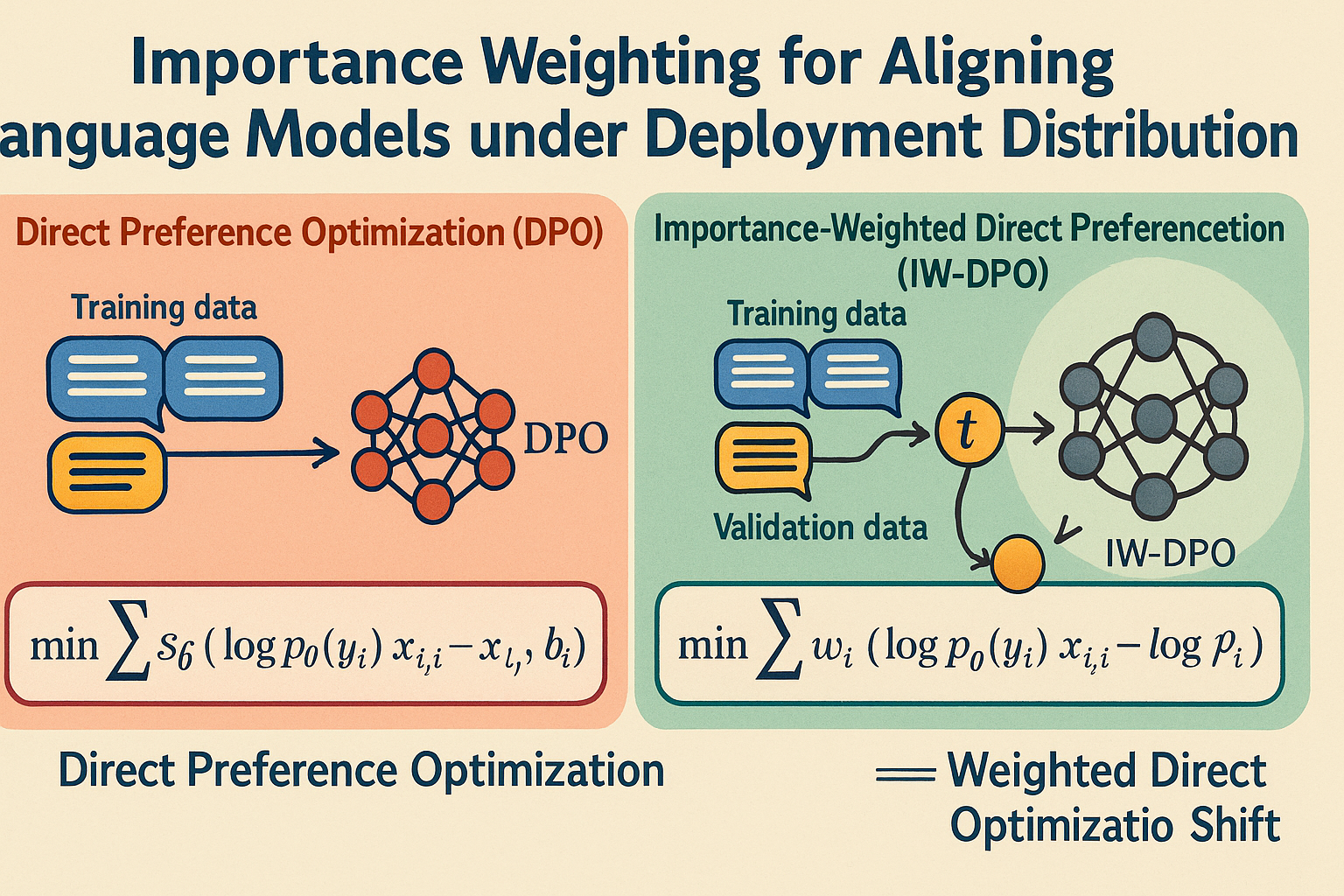
Importance weighting for aligning language models under deployment distribution shift
Thanawat Lodkaew, Tongtong Fang, Takashi Ishida, Masashi Sugiyama
TMLR 2025
Abstract
Aligning language models (LMs) with human preferences remains challenging partly because popular approaches, such as reinforcement learning from human feedback and direct preference optimization (DPO), often assume that the training data is sufficiently representative of the environment in which the model will be deployed. However, real-world applications frequently involve distribution shifts, e.g., changes in end-user behavior or preferences during usage or deployment, which pose a significant challenge to LM alignment approaches. In this paper, we propose an importance weighting method tailored for DPO, namely IW-DPO, to address distribution shifts in LM alignment. IW-DPO can be applied to joint distribution shifts in the prompts, responses, and preference labels without explicitly assuming the type of distribution shift. Our experimental results on various distribution shift scenarios demonstrate the usefulness of IW-DPO.
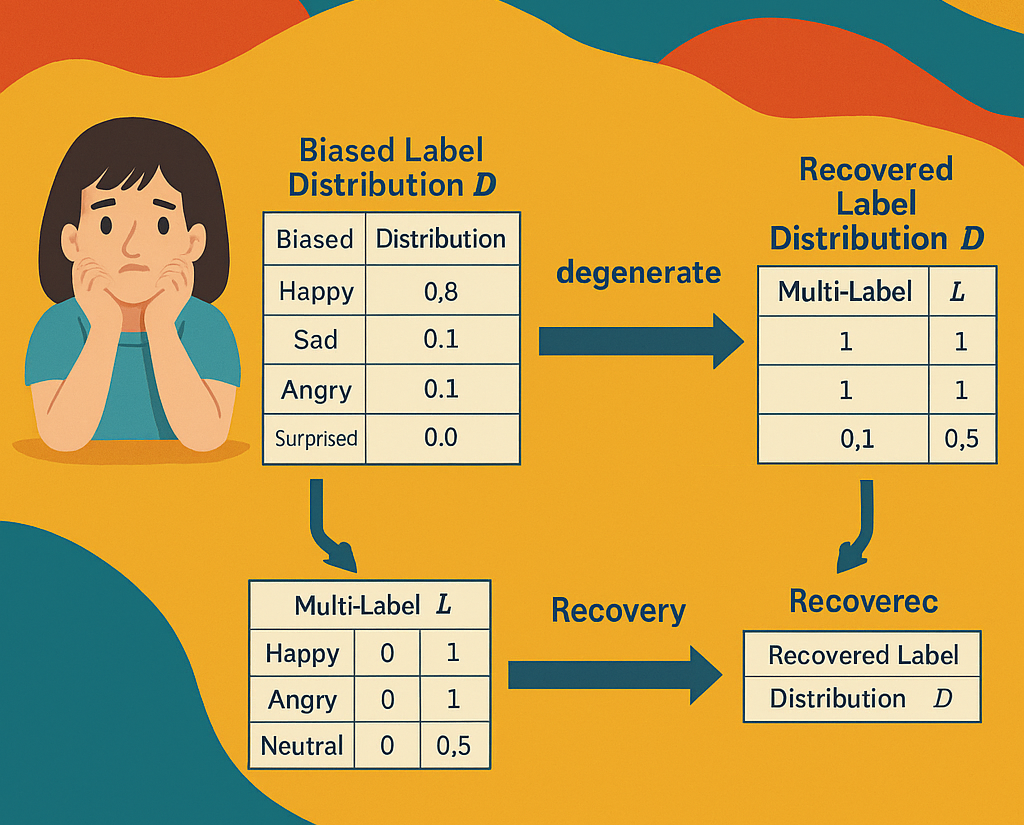
Label distribution learning with biased annotations assisted by multi-label learning
Zhiqiang Kou, Si Qin, Hailin Wang, Jing Wang, Mingkun Xie, Shuo Chen, Yuheng Jia, Tongliang Liu, Masashi Sugiyama, Xin Geng
IJCAI 2025
Abstract
Multi-label learning (MLL) has gained attention for its ability to represent real-world data. Label Distribution Learning (LDL), an extension of MLL to learning from label distributions, faces challenges in collecting accurate label distributions. To address the issue of biased annotations, based on the low-rank assumption, existing works recover true distributions from biased observations by exploring the label correlations. However, recent evidence shows that the label distribution tends to be full-rank, and naive apply of low-rank approximation on biased observation leads to inaccurate recovery and performance degradation. In this paper, we address the LDL with biased annotations problem from a novel perspective, where we first degenerate the soft label distribution into a hard multi-hot label and then recover the true label information for each instance. This idea stems from an insight that assigning hard multi-hot labels is often easier than assigning a soft label distribution, and it shows stronger immunity to noise disturbances, leading to smaller label bias. Moreover, assuming that the multi-label space for predicting label distributions is low-rank offers a more reasonable approach to capturing label correlations. Theoretical analysis and experiments confirm the effectiveness and robustness of our method on real-world datasets.
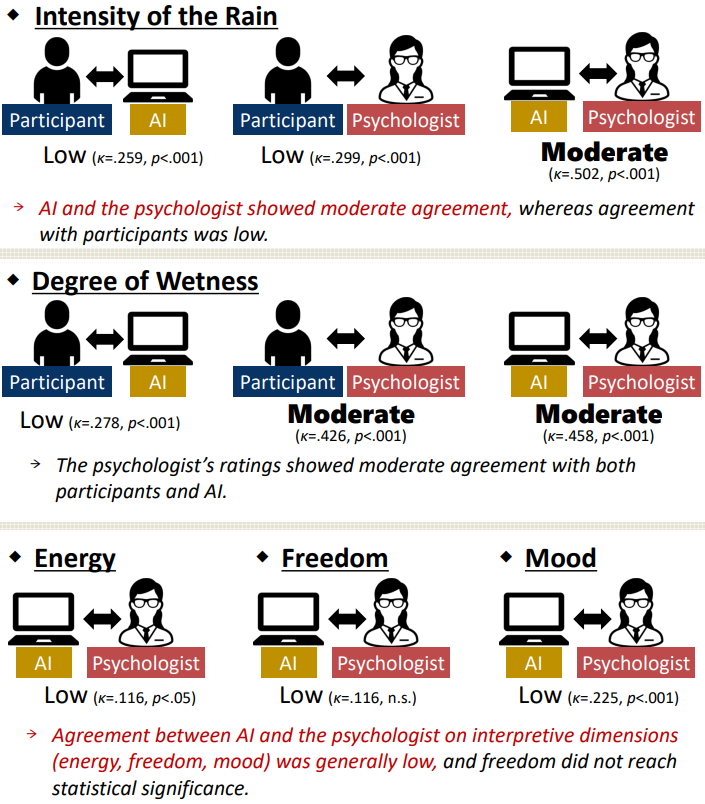
An Exploratory Study on AI-Based Impression Evaluation of the Draw-a-Person-in-the-Rain Test and Its Associations with Psychological Variables
Ami Hirota, Yuka Iwane, Chiaki Kasahara, Takashi Ishida, Masashi Sugiyama, Tongliang Liu, Mari Hirano
KPA 2025
Abstract
This study explored AI-based impression evaluation of the Draw-a-Person-in-the-Rain Test (DPRT) and examined its associations with psychological variables. Sixty high school students completed the DPRT, rated their drawings, and responded to coping and resilience scales. A GPT model (ChatGPT-4o) and a clinical psychologist independently evaluated each drawing on five dimensions: rain intensity, wetness, energy, freedom, and mood. Inter-rater agreement was analyzed using weighted kappa coefficients, and correlations with psychological indicators were examined. AI and the psychologist showed moderate agreement for visually explicit features—rain intensity (κ=.502) and wetness (κ=.458)—but low agreement for more interpretive dimensions such as freedom and energy. Several psychological indicators were associated with ratings from participants, AI, and the psychologist, though some correlations emerged only in AI ratings (e.g., wetness with Planning; energy with Catharsis and Resignation), suggesting that AI may capture visual cues not immediately apparent to human evaluators. Overall, the findings indicate that AI can provide consistent evaluations of concrete visual elements in projective drawings while remaining limited in more nuanced interpretive judgments. AI may serve as a complementary tool, offering additional perspectives in psychological assessment. Future work should build larger and more diverse drawing datasets to enhance the reliability of AI-based impression evaluation.

Recursive reward aggregation
Yuting Tang, Yivan Zhang, Johannes Ackermann, Yu-Jie Zhang, Soichiro Nishimori, Masashi Sugiyama.
RLC 2025
Abstract
In reinforcement learning (RL), aligning agent behavior with specific objectives typically requires careful design of the reward function, which can be challenging when the desired objectives are complex. In this work, we propose an alternative approach for flexible behavior alignment that eliminates the need to modify the reward function by selecting appropriate reward aggregation functions. By introducing an algebraic perspective on Markov decision processes (MDPs), we show that the Bellman equations naturally emerge from the recursive generation and aggregation of rewards, allowing for the generalization of the standard discounted sum to other recursive aggregations, such as discounted max and Sharpe ratio. Our approach applies to both deterministic and stochastic settings and integrates seamlessly with value-based and actor-critic algorithms. Experimental results demonstrate that our approach effectively optimizes diverse objectives, highlighting its versatility and potential for real-world applications.
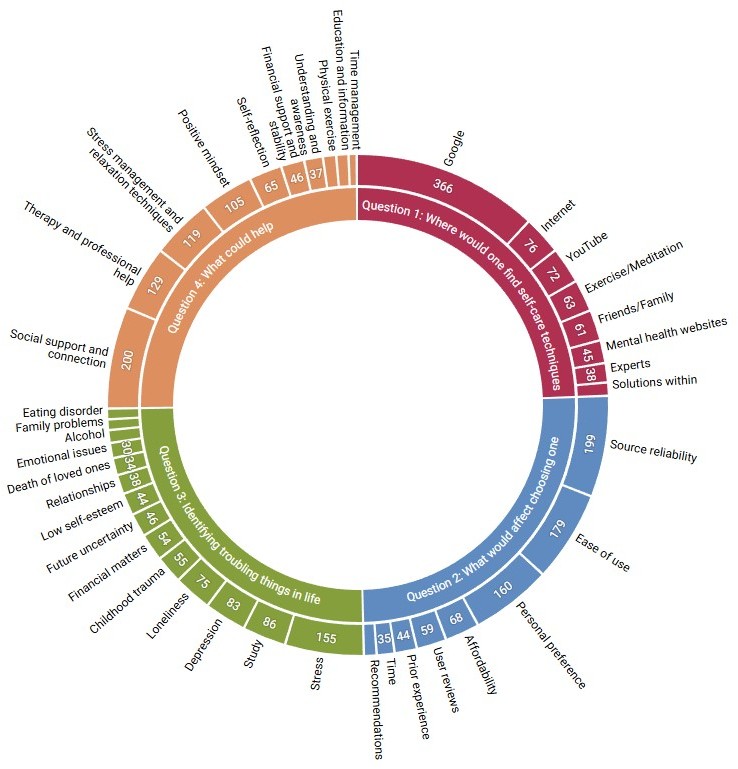
Investigating mental wellbeing self-care in higher education using BERTopic modeling
▷ Project Video
Mahmoud Ali, Niels van Berkel, Benjamin Tag, Ville Paananen, Jonas Oppenlaender, Koji Yatani & Simo Hosio
Discover Mental Health (2025)
Abstract
Addressing the mental wellbeing of higher education students is urgent, given rising distress rates and significant help-seeking gaps. Students face various life challenges ranging from academic pressure and career concerns to global issues like climate change, all of which may negatively impact their mental wellbeing. While appropriate self-care can mitigate these challenges, understanding the strategies students use independently is key to developing accessible support. This article analyses contemporary triggers for mental distress and the corresponding self-care strategies adopted by students, based on data collected during the COVID-19 pandemic. We then discuss how these findings can inform the design of future digital mental wellbeing solutions. We conducted an online study with 810 participants, utilizing computational methods to analyse open-ended data. We present insights into prevalent challenges and self-care strategies, deriving direct implications for design. Finally, we discuss how technology designers can contribute to effective mental wellbeing solutions based on our findings.